Prompt Engineering 基础
目录
要让chatgpt回答更准确、专业,prompt engineering必不可少,以下是最近读了相关资料的一些总结
基础 #
- Prompt 里最好包含完整的信息
- 【badcase】
Write a poem about OpenAI. - 【goodcase】
Write a short inspiring poem about OpenAI, focusing on the recent DALL-E product launch (DALL-E is a text to image ML model) in the style of a {famous poet}
- 【badcase】
- Prompt 最好简洁易懂,并减少歧义
- 【case】
Use a 3 to 5 sentence paragraph to describe this product.
- 【case】
- 尽量告诉LLM应该做什么,而非not to do
- 增加示例
- 【case】
Prompt:Q1 -> A1;Q2 -> A2;Q3 ->
- 【case】
- 角色设定
- 【case】
You are a primary school teacher who can explain complex content to a level that a 7 or 8 year old child can understand.
- 【case】
用法 #
-
问答
-
推理
- 如果你想用 ChatGPT API 做点什么小应用,我建议可以从这个场景入手,相对来说没有其他场景那么红海
-
生成
- 写代码
-
改写
- 翻译:将中文文档翻译成英文,亦或者将英文翻译成中文。关于翻译,我还想强调,像 ChatGPT 除了能翻译人类的语言外,还能翻译编程语言,比如将 Python 代码翻译成 Haskell 代码。
- 修改:修改内容的语法,甄别内容里的错别字。
- 润色:润色文章,将内容改成另一种风格
- 【case】
You are a primary school teacher who can explain complex content to a level that a 7 or 8 year old child can understand. Please rewrite the following sentences to make them easier to understand: {Text} - 【case】
Imagine you are the famous writer David Foster Wallace, please rewrite this sentences.
-
信息解释
- 【case】
Explanation of what the code does: - Python 3 - def remove_common_prefix(x, prefix, ws_prefix): - x["completion"] = x["completion"].str[len(prefix) :] ```
- 【case】
-
信息总结
-
【case】
Extract the important entities mentioned in the article below. First extract all company names, then extract all people names, then extract specific topics which fit the content and finally extract general overarching themes
Desired format:
Company names: <comma_separated_list_of_company_names>
People names: -||-
Specific topics: -||-
General themes: -||- ([View Highlight](https://read.readwise.io/read/01gy1g4vw1p02yzr2e18dgw3hd))
- Text: """Powering Next Generation ..."""
【case】让模型输出特定的结构化答案(比如JSON/Markdown等)。 也可以方便集成更多的额外要求, 比如增加一个"confidence level", 并通过 prompt 的形式指定这些数值的格式与甚至区间
{context}
Question: What is bond duration mentioned here.
Answer template (Valid JSON format):{{"duration": $duration_numeric_value_in_year, "confidence_level": $answer_confidence_level_high_moderate_or_low, }}
Answer:
- 信息提取
- 使用 ”“” 或 ### 符号将指令和需要处理的文本分开
- 【case】
Please summarize the following sentences to make them easier to understand. Text: """ {TEXT} """
Models #
- frame1:
- Instruction(必须): 指令,即你希望模型执行的具体任务。
- Context(选填): 背景信息,或者说是上下文信息,这可以引导模型做出更好的反应。
- Input Data(选填): 输入数据,告知模型需要处理的数据。
- Output Indicator(选填): 输出指示器,告知模型我们要输出的类型或格式
- frame2: CRISPE
- CR: Capacity and Role(能力与角色)。你希望 ChatGPT 扮演怎样的角色。
- I: Insight(洞察力),背景信息和上下文(坦率说来我觉得用 Context 更好)。
- S: Statement(指令),你希望 ChatGPT 做什么。
- P: Personality(个性),你希望 ChatGPT 以什么风格或方式回答你。
- E: Experiment(尝试),要求 ChatGPT 为你提供多个答案
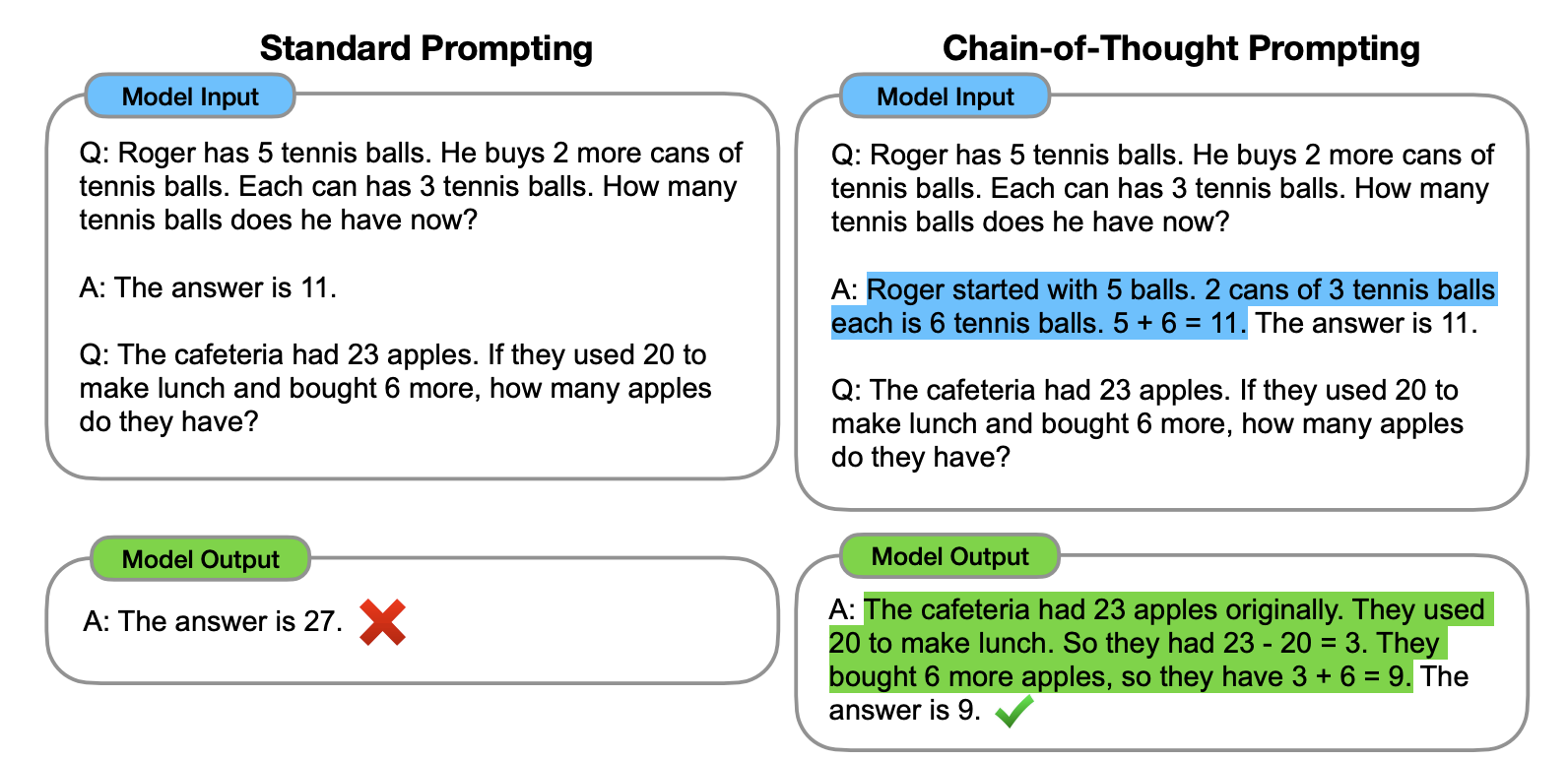
- Chain of Thought
- 只需要在问题的结尾里放一句
Let‘s think step by step,模型输出的答案会更加准确 - 也可以用
Let's work this out in a step by step way to be sure we have the right answer - 仅在使用大于等于 100B 参数的模型时,才会生效
- 只需要在问题的结尾里放一句
- 通过向大语言模型展示一些少量的样例,并在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果
-
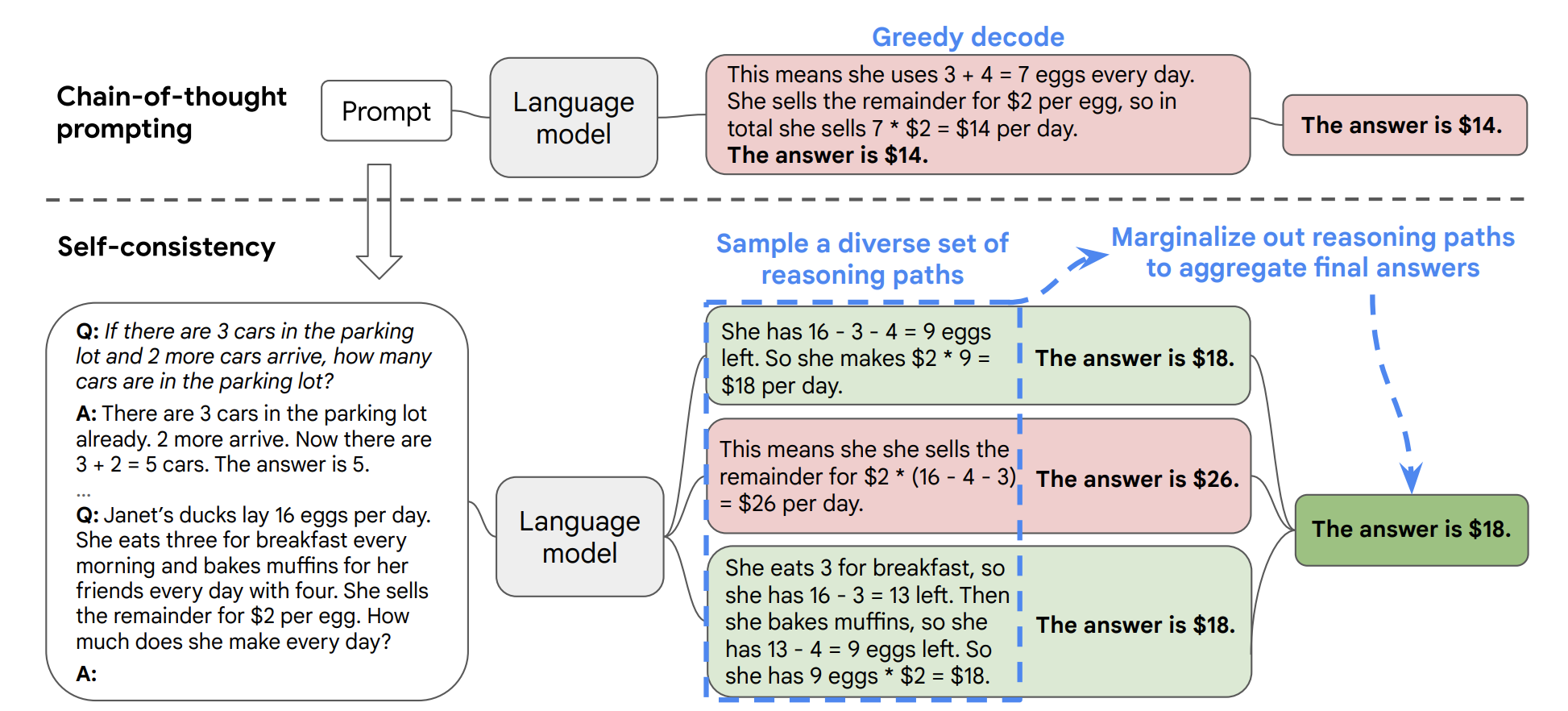
- Self-Consistency
- 是对 Chain of Thought 的一个补充,它能让模型生成多个思维链,然后取最多数答案的作为最终结果
-
- PAL Models (Program-Aided Language Models)
- 在 prompt 里引入代码,并引导模型使用代码来运算和思考
-